Traditional disk-based swap mechanisms, while extending usable memory for modern memory-intensive workloads, suffer from significant performance overhead due to high I/O latency. Zram mitigates this by compressing memory pages in RAM, but its performance is highly dependent on the chosen compression algorithm, which involves a trade-off between memory efficiency and speed. Existing static algorithm choices fail to adapt to dynamic system conditions.
To address this, we propose the dynamic switching algorithm, a runtime mechanism that intelligently selects the optimal Zram compression algorithm (e.g., LZ4, ZSTD) based on real-time memory pressure.
- Author: Tso-Fei Yen, Chao-Qun Wang (me), and Jun-Hao Tso
- Paper link: dynamic-zram.pdf
- Slides link: dynamic-zram-slides.pdf
Dynamic Switching Algorithm¶
To design a dynamic switching mechanism between compression algorithms, a rigorous evaluation of potential candidates is essential. We benchmarked algorithms utilized by Zram in Linux kernel 6.12: Deflate, LZ4, LZ4HC, LZO, and ZSTD. The evaluation was conducted using lzbench with the Silesia compression corpus to assess compression performance.
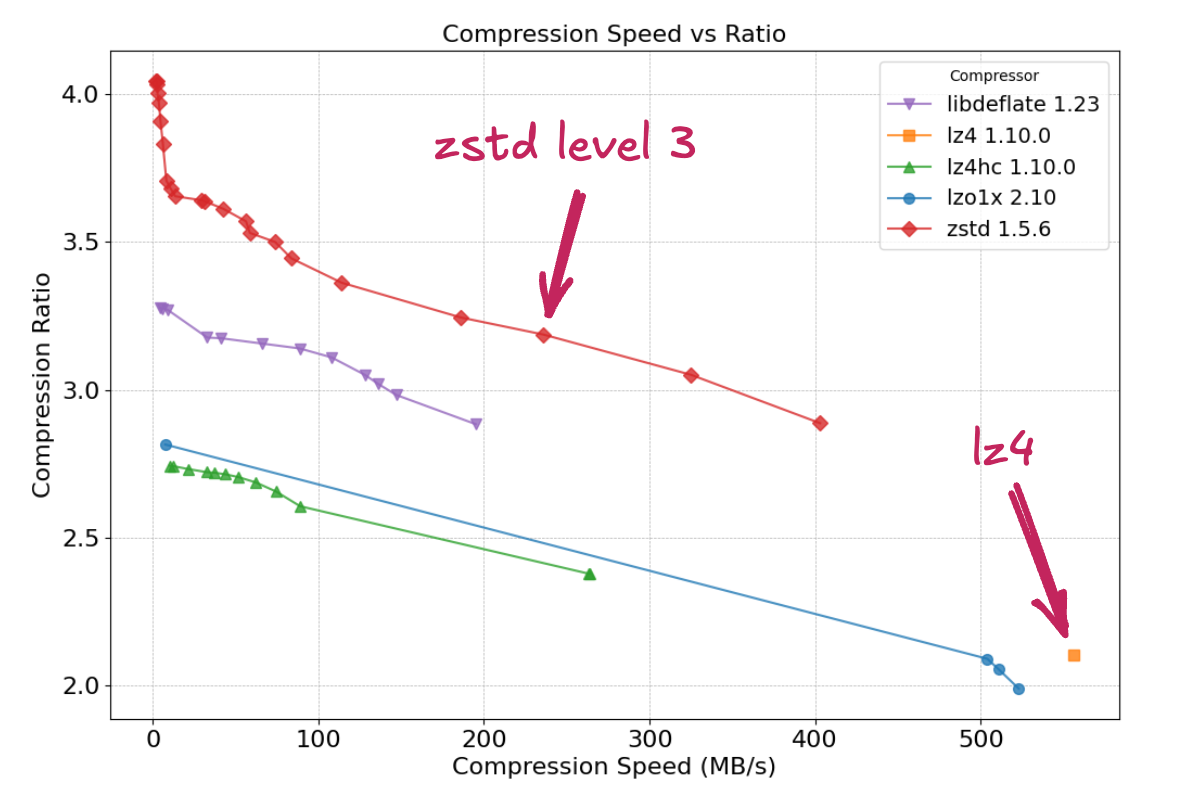 Compression Ratio and Speed of Algorithms in Zram
Compression Ratio and Speed of Algorithms in Zram
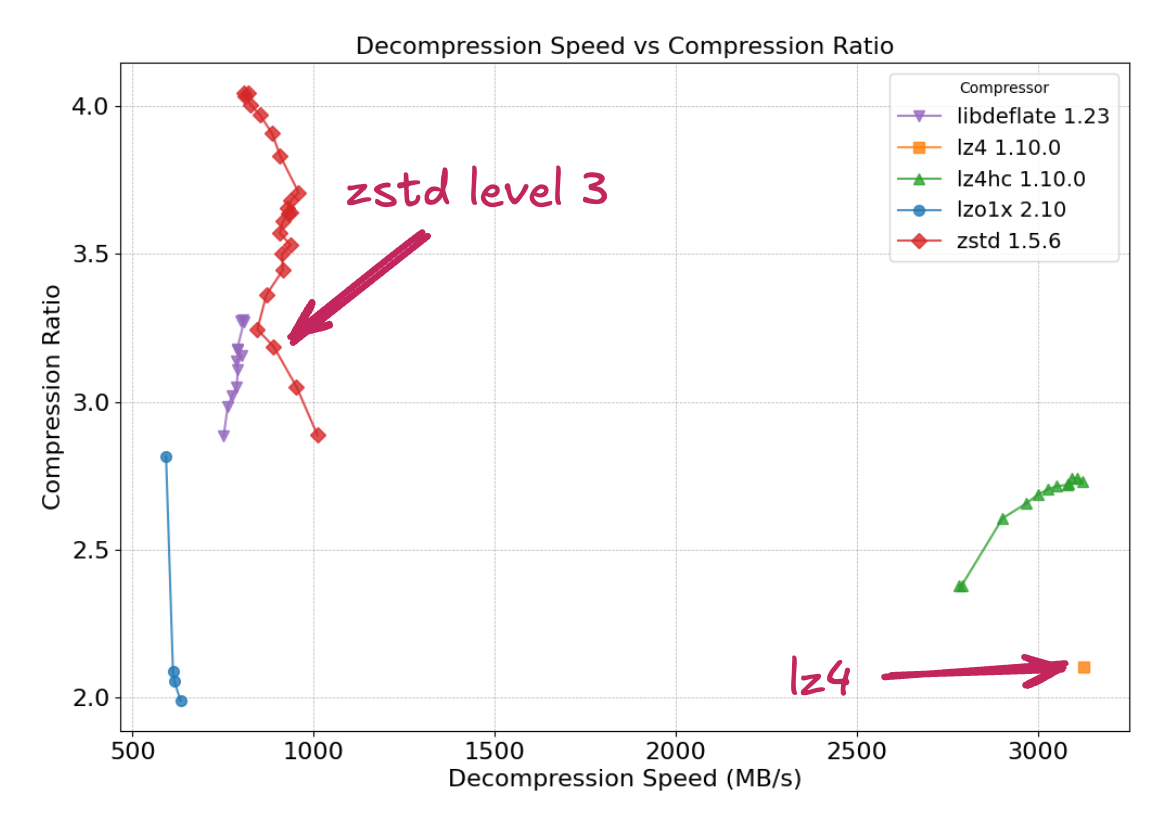 Decompression Ratio and Speed of Algorithms in Zram
Decompression Ratio and Speed of Algorithms in Zram
Having identified LZ4 and ZSTD as suitable algorithms for the dynamic switching algorithm, the next critical step is to define the conditions under which these algorithms will be interchanged. Given that the primary concern is RAM pressure, Zram's RAM usage was selected as the key criterion for triggering algorithm switches.
The proposed mechanism operates as follows:
- If Zram's RAM usage falls below a predetermined threshold, the dynamic switching algorithm will switch to LZ4. This prioritizes compression speed, which is beneficial when memory resources are ample.
- Conversely, if Zram's RAM usage exceeds this threshold, the dynamic switching algorithm will switch to ZSTD. This prioritizes a higher compression ratio, mitigating the risk of Out-Of-Memory (OOM) by conserving RAM.
Evaluation¶
The primary objective of these benchmarks was to demonstrate that the dynamic switching algorithm achieves superior availability compared to LZ4, while also exhibiting higher throughput than ZSTD. Better availability in this context signifies a reduced likelihood of encountering OOM errors. Consequently, benchmark scenarios were carefully designed where Zram configured with LZ4 would consistently trigger OOM events, whereas both the dynamic switching algorithm and ZSTD would sustain operation.
The benchmark comprised a three-phase sequence:
- Memory Fill Phase: System memory was intentionally exhausted by filling it with random data to trigger swap-out operations.
- Memory Free Phase: A portion of the allocated memory was released to reduce memory pressure.
- Swap I/O Phase: Repeated swap-in and swap-out operations were induced by cyclically writing to all pages, simulating active memory usage.
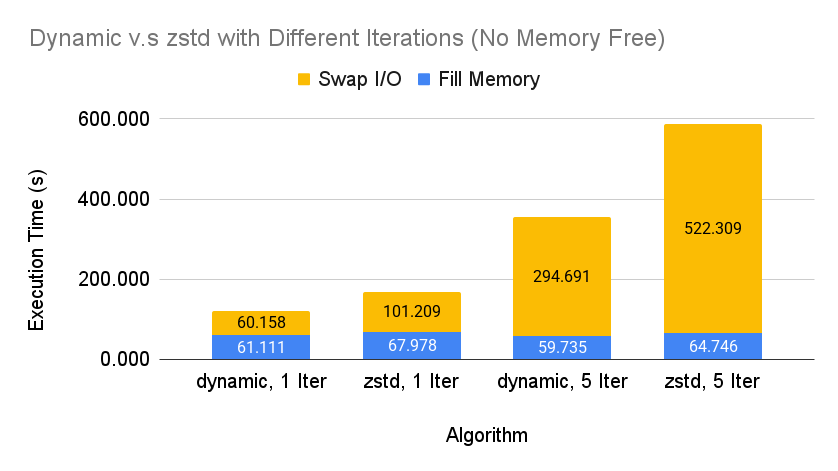 Execution Time of Dynamic Switching Algorithm and ZSTD without Free Memory Phase.
Execution Time of Dynamic Switching Algorithm and ZSTD without Free Memory Phase.
 Execution Time of Dynamic Switching Algorithm and ZSTD with Free Memory Phase.
Execution Time of Dynamic Switching Algorithm and ZSTD with Free Memory Phase.
Conclusions¶
From the benchmark results, we conclude that the dynamic algorithm contributes to two key features.
- Higher availability compared to static LZ4 algorithm: From both benchmarks, we could see that static LZ4 leads to OOM conditions, but dynamic algorithm did not lead to such unfavorable situations by switching to a better-compressed algorithm (ZSTD) once Zram memory pressure reaches a certain threshold.
- Faster process execution time compared to static ZSTD algorithm: From the single-task benchmark, we see that dynamic algorithm leads to a much faster process execution time by using a faster-compressed algorithm (LZ4) initially, lowering CPU time used for compressing pages. Even though the result is not obvious in the multi-process benchmark, we conclude that this is a benchmark design problem, and once the timeline is stretched to a longer and larger scale, the benefits could be more obvious.
In essence, the dynamic algorithm significantly enhances both system stability and performance by intelligently adapting its compression strategy based on real-time memory conditions.